Copyright © 2015 Powered by MWeb, Theme used GitHub CSS.
先说说我的简历,毕业刚出来做推荐,在1号店,后来觉得做业务没意思,就各个公司浪了一圈,目前在做Machine Learning Infrastructure。 最近也在和好朋友聊过很多recsys相关的思考, 整理了下,分享给大家
游江海、涉山川,寻师访道为参禅;自从认得曹溪路,了知生死不相关。行亦禅、坐亦禅,语默动静体安然;纵遇锋刀常坦坦,假饶毒药也闲闲。 --\《证道歌\》 永嘉玄觉禅师
修禅即体悟当下, 从个体的角度去感悟,从一个人的角度去了解推荐系统要做啥?
简单地百度下, 都不用Google,就有很多的答案。 其实提炼下没那么多的东西,无非就以下几个工作内容:
数据收集是一个没有信息熵的词, 在互联网中,数据收集这个词你去问不同的同学, 会得到不同的答案, 对于算法同学,数据收集是啥样的呢?
找对人
一定要找到数据的对接人, 公司大了, 数据的产生、使用都有一定的标准流程,流程越长,越难理解数据表中指标的意义,一定要找到合适的人, 他不仅能告诉你数据的意义,更多的时候可能会告诉你还有哪些有意义的数据, 无论做什么工作一定要是很靠谱的合作方,尤其是在这个流程你可能不太明白的情况下, 在我们公司, 数仓开发,是最复杂的功能,他们对接几乎所有的算法团队的数据需求,他们可能是公司中最了解数据的同学,但是他们中的大多数同学因为本身工作的特殊性,有的时候是小伙伴口中自嘲的”sql boy“, 他们很难去理解算法同学对数据真实的一些需求;因而,简单地沟通,其实很多因为彼此知识的不对等,造成提供的和需求的不一致,而且这种比想象的要多的多,和你的业务数据提供方交朋友,可能是最无需成本的沟通;
找哪样的数据
作为需求方, 算法同学一定要知道去拿哪些数据,推荐是一个向人推荐物的过程,用户的特征是首要的,完整的用户画像是极为重要的,了解你的用户是什么样的人,有什么样的属性,喜欢什么,什么时候最活跃等等;其次,了解你的物料,如果是电商,那就是你的商品,你的物料数据在哪儿? 这些数据有哪些维度?是怎样组织的,你需要怎么去做处理?我相信正常的团队,一定有专门作用户画像与物料特征的同学,去和这样的团队沟通,了解他们做了什么,如何去使用他们的数据,甚至是否合作,你也可以去做一些数据挖掘的活,去扩展他们团队没有考虑到的特征维度。
道即万物运行的轨迹,虽然每个个体都不同
Item 是数据系统中的『物』,理解『物』和借『人』是数据系统本身最核 心的两个方面,本章为方便描述,将以电商场景下的数据系统中对『物』的理解。
这里仅以电商为例,仅表达在通常到算法同学手上之前,已经经过很多比较复杂的系统来进行抽象,一个好的数据工作人员也应该有一些基础的了解,比如针对供应链体系的电商化的数据体系。
SPU(Standard Product Unit)标准化产品单元,即以产品为一个单元, 如华为 mate 20 pro,就是一个 SPU,主要是描述产品,但是通常对一个用 户看到的产品会有其他的属性来描述,如内存大小:64g、128g 的价格明显不 一致,子型号等等,因此,SPU 不足以应用在数据系统中,而 SKU(Stock Keeping Unit)针对的是不同规格的商品,商品的所有不同规则的组合就是一个SKU,如下图所示:
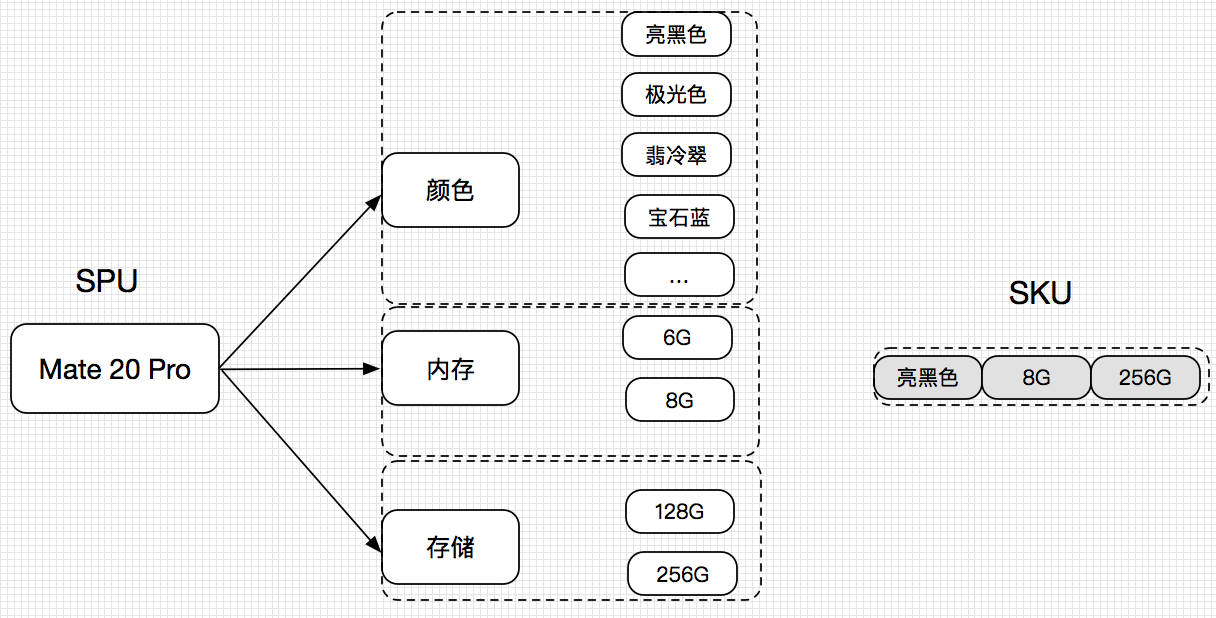
而本章将从类目属性、基础属性、UGC,PGC 三个维度来讲述如何理解 电商中的 Item:SKU。
类别也是描述 sku 的一部分信息,电商体系的商品类目〸分复杂,通常类目体系分为三级(以前在1号店工作经验,现在也应该是一致的),以京东页面为例:

电商类目体系实际上是三层(或者更多)的树,叶子节点也就是第三级类目数量大概是 数千个(以前接触大概是 3000 多个,现在大厂的类别体系规模可能更大),每一个sku 类目信息有这三级构成。
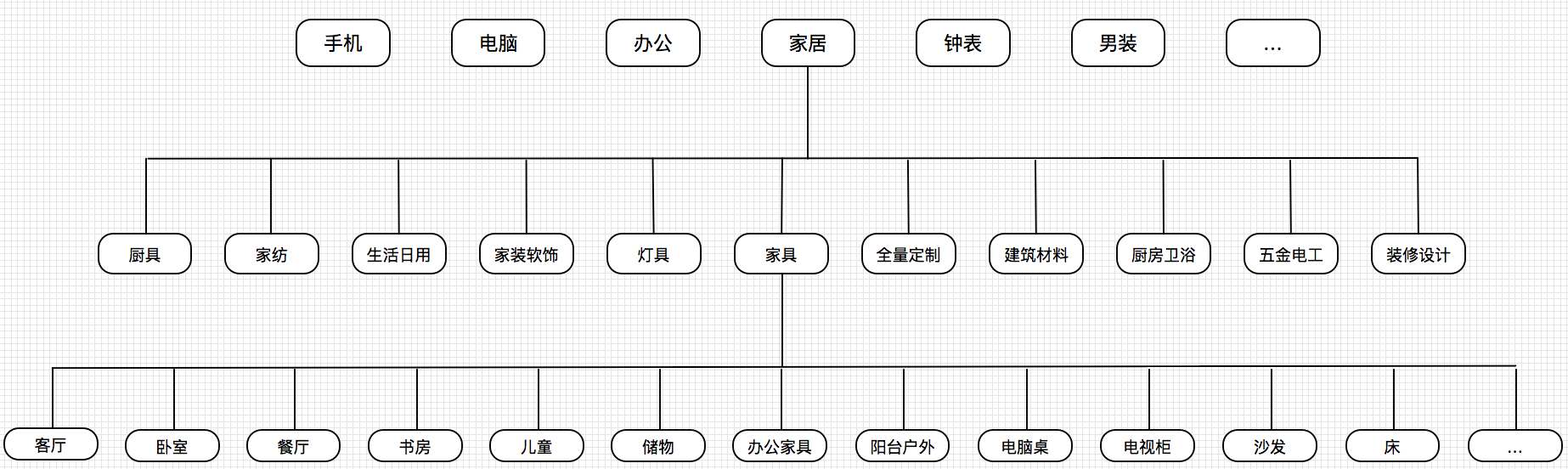
上图是京东首页的家居-家具的一些子类目示意图,这些类目本身是特别有信息量的,而这部分信息由于是商家在商家商品时去选择的,其实还是比较有工作量的,另外只要人参与,就会出错,有的时候由于电商本身对一些类目 有补贴、优惠,商家会出于利益的目的,故意选错类目,这些噪声,对于理解 SKU 是有负向作用的,为减少工作量以及减少分类错误率,引入机器学习算 法对商品进行自动化分类是很有必要的。
考虑到搜索、推荐等核心业务都调用商品的类目数据,为了降低类目错误 对核心业务的影响,可以使用机器学习方法设计模型通过商品标题来对商品进 行分类,即可定位为文本分类问题,且由于商品标题均不长,为短文本分类问 题。
传统文本分类方法
频次法: 顾名思义,〸分简单,记录每篇文章的次数分布,然后将分布输 入机器学习模型,训练一个合适的分类模型,对这类数据进行分类,需要指出 的时,在统计次数分布时,可合理提出假设,频次比较小的词对文章分类的影 响比较小,因此我们可合理地假设阈值,滤除频次小于阈值的词,减少特征空 间维度
TF-IDF:相对于频次法,有更进一步的考量,词出现的次数能从一定程 度反应文章的特点,即 TF,而 TF-IDF,增加了所谓的反文档频率,如果一 个词在某个类别上出现的次数多,而在全部文本上出现的次数相对比较少,我 们认为这个词有更强大的文档区分能力,TF-IDF 就是综合考虑了频次和反文 档频率两个因素。
互信息方法:也是一种基于统计的方法,计算文档中出现词和文档类别的 相关程度,即互信息
N-Gram:基于 N-Gram 的方法是把文章序列,通过大小为 N 的窗口, 形成一个个Group,然后对这些 Group 做统计,滤除出现频次较低的Group, 把这些 Group 组成特征空间,传入分类器,进行分类。
基于深度学习文本分类方法
这部分后续要详细扩展,现在先不卡在这儿了
TextCNN: 基于 cnn 的文 本分类方法,使用不同大小 filter 的 cnn 网络,filter 的大小即为词上下文长 度,如下图,红色为 2k,黄色为 3k,不同 filter 形成不同的 feature map,最后经过 maxpool,将所有的 channel 拼接到一起基于 cnn 的方法,设计不同 的上下文长度来建模上下文关系,但是很明显,丢失大部分的上下文关系。
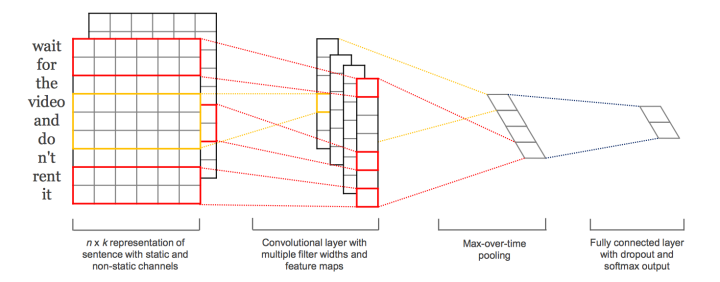
rcnn: rcnn 将每一个词表示为向量化,这个向量化过程会考虑上文与下 文关系,是一个双向过程,整个网络设计如下:
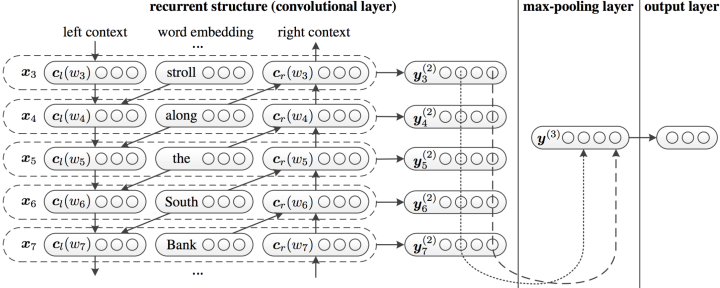
以”A sunset stroll along the South Bank affords an array of stunning van- tage points” 为例:stroll 的表示包括 c l (stroll), preword2vec(stroll), c r (stroll), c l (stroll) 编码”A sunset” 的语义,而 c r (stroll) 向量化过程会考虑下文”along the South Bank affords an array of stunning vantage points” 的语义信息,每 一个词都如此处理,因此会避免普通 cnn 方法的上下文缺失的信息。LSTM 基于 CNN 的方法中第一种类似,直接暴力地在 embedding 之后加入 LSTM, 然后输出到一个 FC 进行分类,基于 LSTM 的方法,我觉得这也是一种特征 提取方式,可能比较偏向建模时序的特征;
C-LSTM C-LSTM 将 embedding 输出不直接接入 LSTM,而是接入到 cnn,通过 cnn 得到一些序列,然后把这些序列再接入 到 LSTM 来分类。
char-cnn char-cnn 不依赖分词工具,直接将字引入 cnn 中,尤其在短文本分类场景中,分词后,词出现频率极度稀疏,而字级别的 char-cnn 相对频率较高,效果更好。
Pretrain model based Bert 当然还有基于Bert这类模型来finetuning进行文本分类的模型,基于Transformer改造的超大的模型, 并且已经取得STOA效果,下篇文章会在某个真实数据集上详细对比一些经典模型;
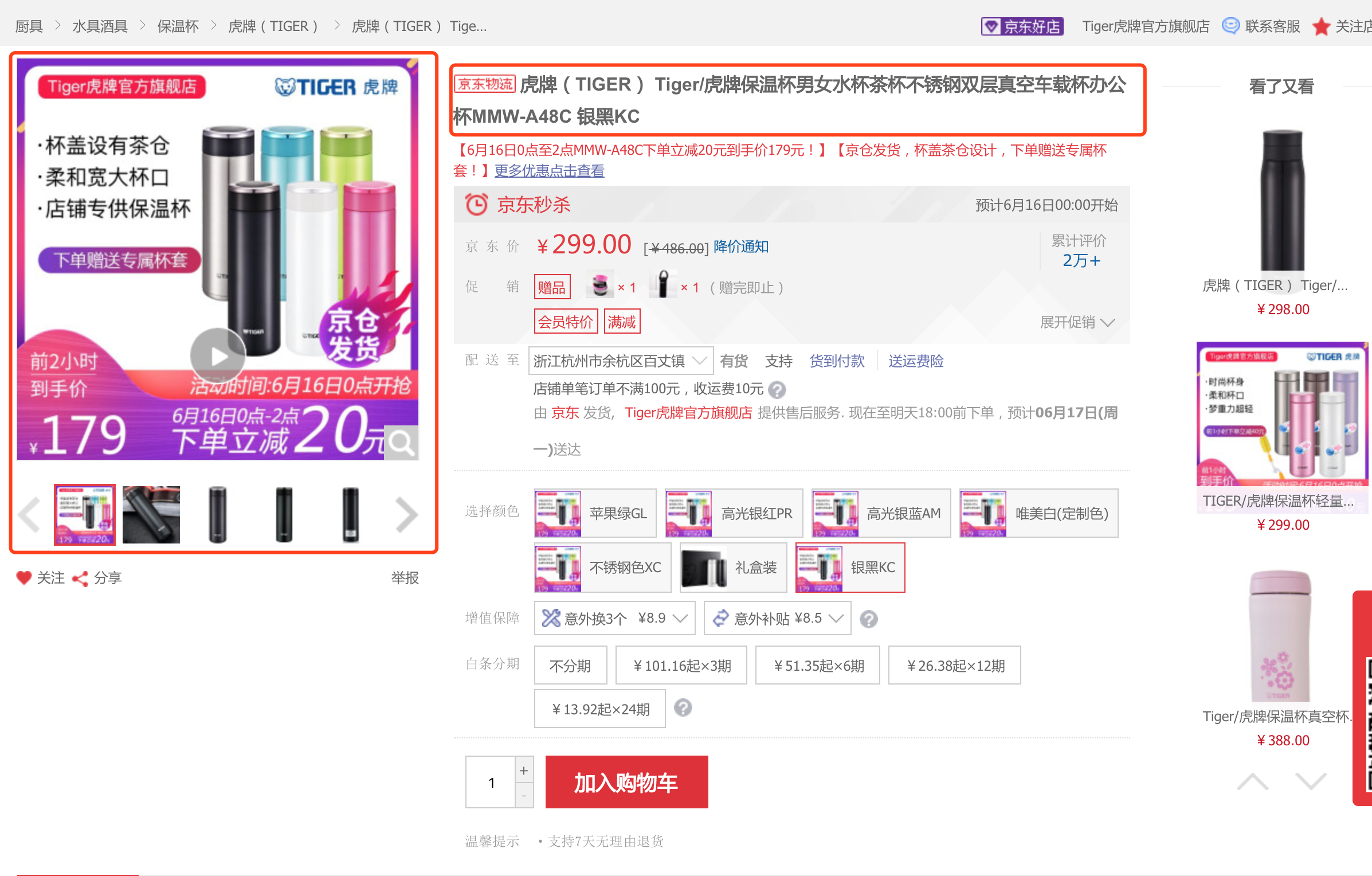
下图是京东的页面上,华为 mate20 pro 8g+128g 版本的,可以看出 SKU 是由一套自由的属性值组合,比如品牌:华为、内存:8g、CPU:海思等等, 在电商场景下每一个类别都有不同的属性,这些不同属性没有严格的层次机 构, 很难像常规的特征工程量化这部分信息, 且属性、属性值的体系随着 sku 的添加会一直动态扩展, 通常这部分特征会以 key-val 形式 ID 化保存。

经过处理之后,mate 20pro,在数据系统中,基础属性部分的特征可以这样表示:
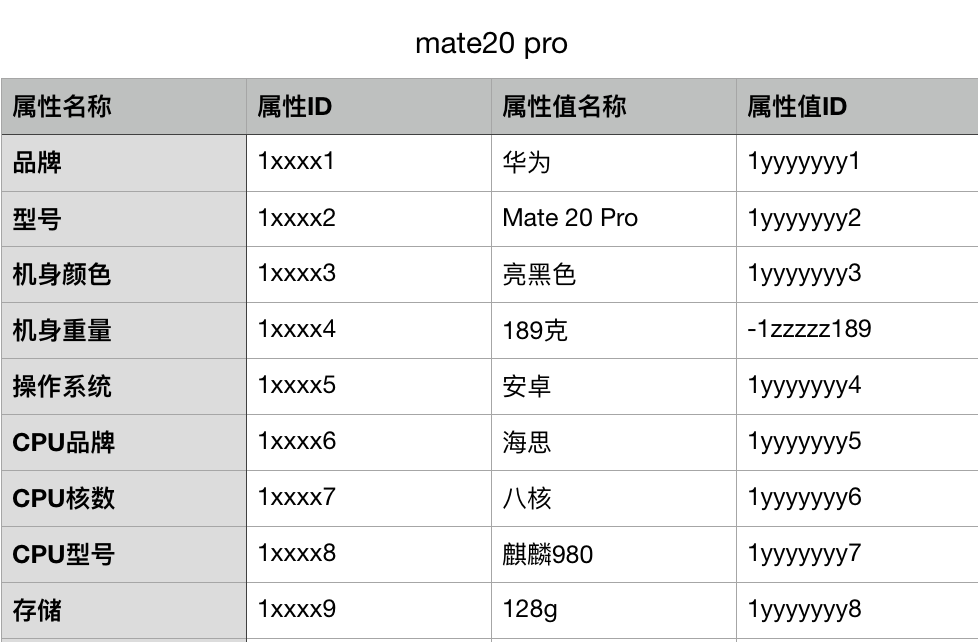
如此,一个sku 可以由这些属性 ID 与属性值 ID 表示,所有的信息就如此的 ID 化,当然有一些如机身重量这样的属性,其属性值可能为连续值,可以选择编码其ID为负数(简单举例,仅表达应具有区别度,实际不一定适用类似方法),并将数值编码到负数 ID 中,即说明该 feature 为连续值,后续可做离散化处理;
sku特征的第三类来源于 UGC 或者 PGC 的内容,如通过对电商标题、展示图像这类PGC信息的挖掘尝试的特征,以及通过用户评论、负反馈、各种不同行为如分享到社交网络、加车后删除等等。
Copyright © 2015 Powered by MWeb, Theme used GitHub CSS.