动机
写这篇文章初衷是最近工作在做一些关于机器学习流程化的工作。现阶段,算法上的创新一天一个样,很多时候,算法同学会去试, 如何能搞提升较高的效率, 每个算法同学的手段都不同,回想计算机科学发展至今天,从野蛮生长到模块化、流程化、标准化。机器学习无外如是。而最近工作涉及到关于mlops相关的事情,其难度很大,不在乎技术本身,当中涉及到太多的以往的技术债。很难去设计本来mlops应该做的东西,另外在某个微信群里讨论,算法同学应该怎样增加工程能力
其实个人认为算法相关的工程能力也不是去一定专注model service,写部署服务这些,个人认为凡是提升算法工程当中的效率,皆可以算作工程能力。基于这两个原因以及自己的职业规划,细了解了开源相关的工作,窃以为开源虽然有时候很难落地企业实际场景,但是其思想很纯粹, 值得我们去学习,这一系列的文章应该会比较多,今天先介绍cml 和dvc。
cml 第一次尝试
git clone https://github.com/burness/example_cml
定义一个train-my-model的workflow:
name: train-my-model
on: [push]
jobs:
run:
runs-on: [ubuntu-latest]
container: docker://dvcorg/cml-py3:latest
steps:
- uses: actions/checkout@v2
- name: cml_run
env:
repo_token: ${{ secrets.GITHUB_TOKEN }}
run: |
pip install -r requirements.txt
python train.py
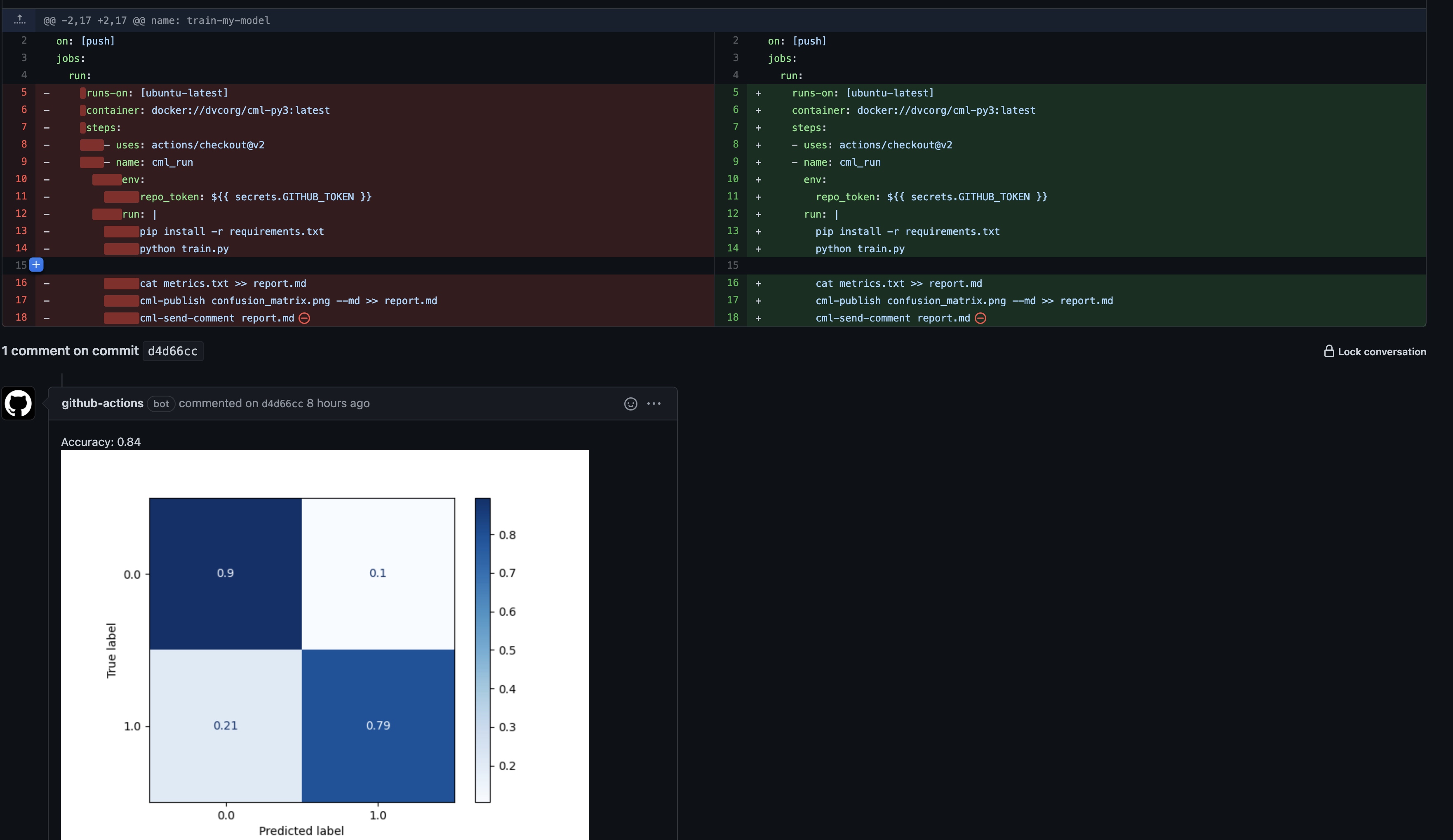
cat metrics.txt >> report.md
cml-publish confusion_matrix.png --md >> report.md
cml-send-comment report.md
几个关键点:
- 定义一个train-my-model的工作流,该工作流在代码被push到仓库当中任一分支时触发;
- 启动dvcorg/cml-py3:latest 容器,使用action/checkout@v2,拉取项目源码(这个是在github专门提供的机器上完成的,github hosted runner和self hosted runner的差异);
- 从requirements.txt安装项目所需python包,运行train.py, 并将结果(metrics.txt, cufusion_matrix.png)重定向到report.md,然后将report转换为下图的评论;
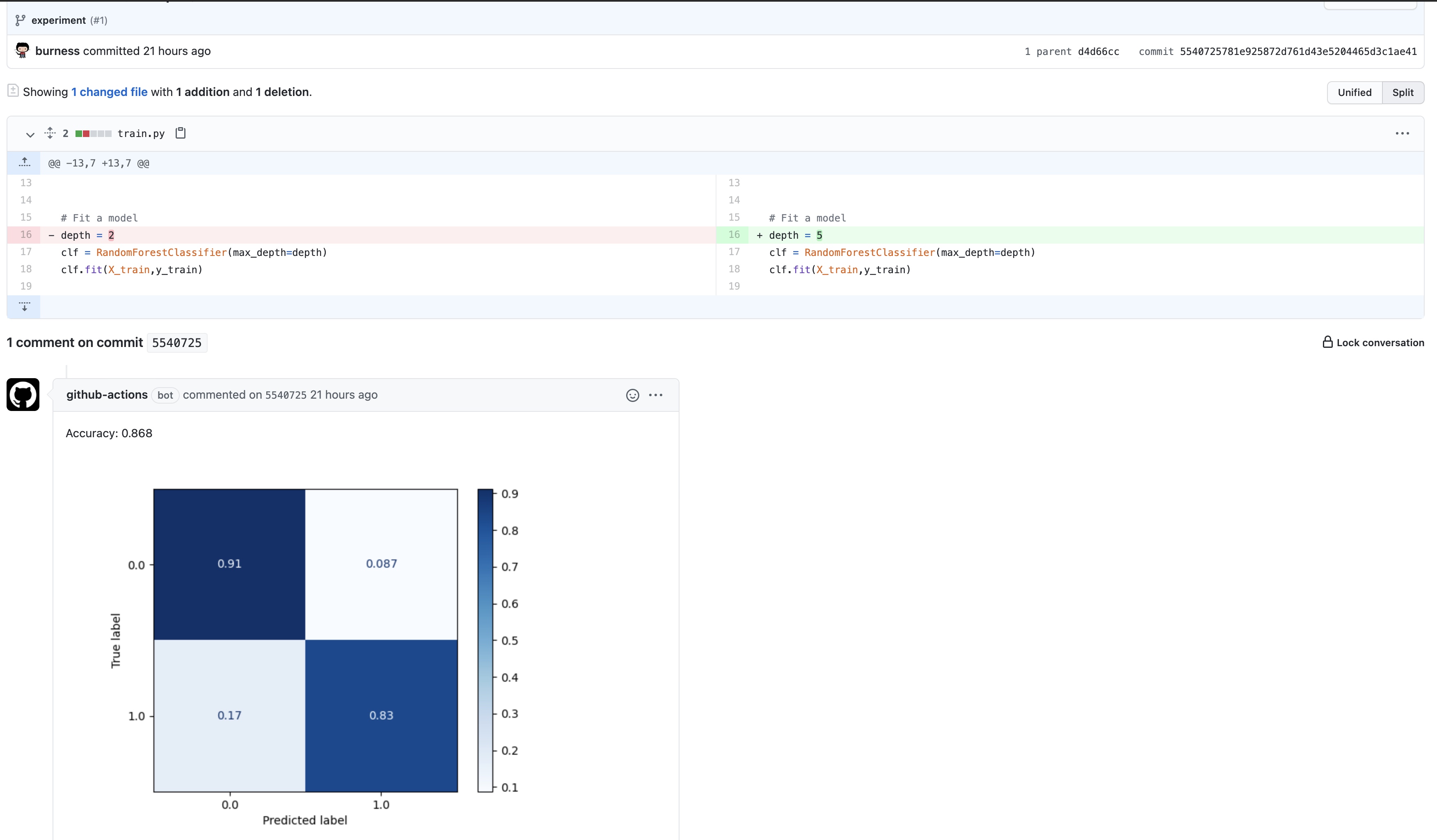
修改代码当中模型某一参数后, 提交后,触发该工作流:
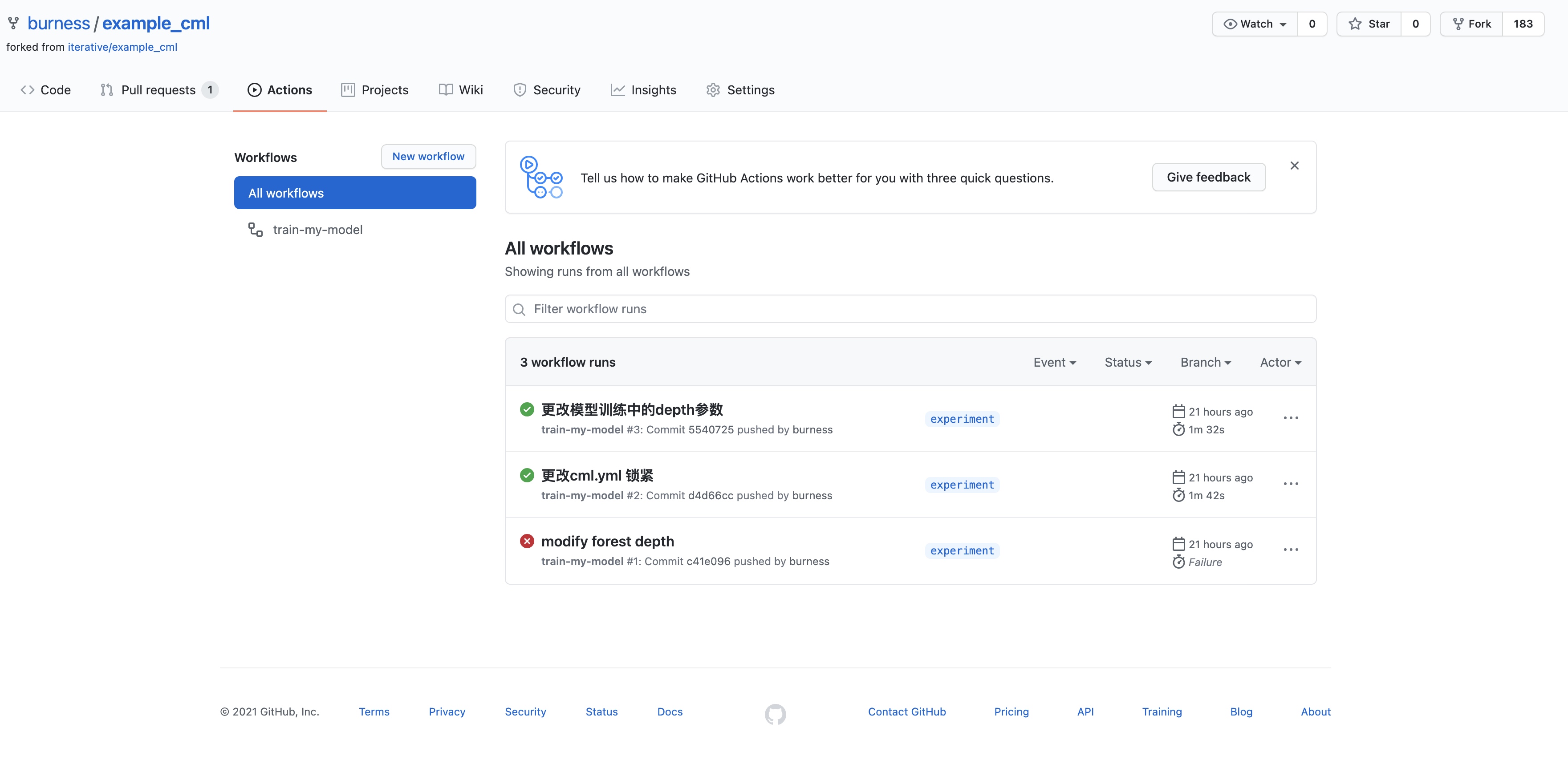
查看任意工作流的日志记录:
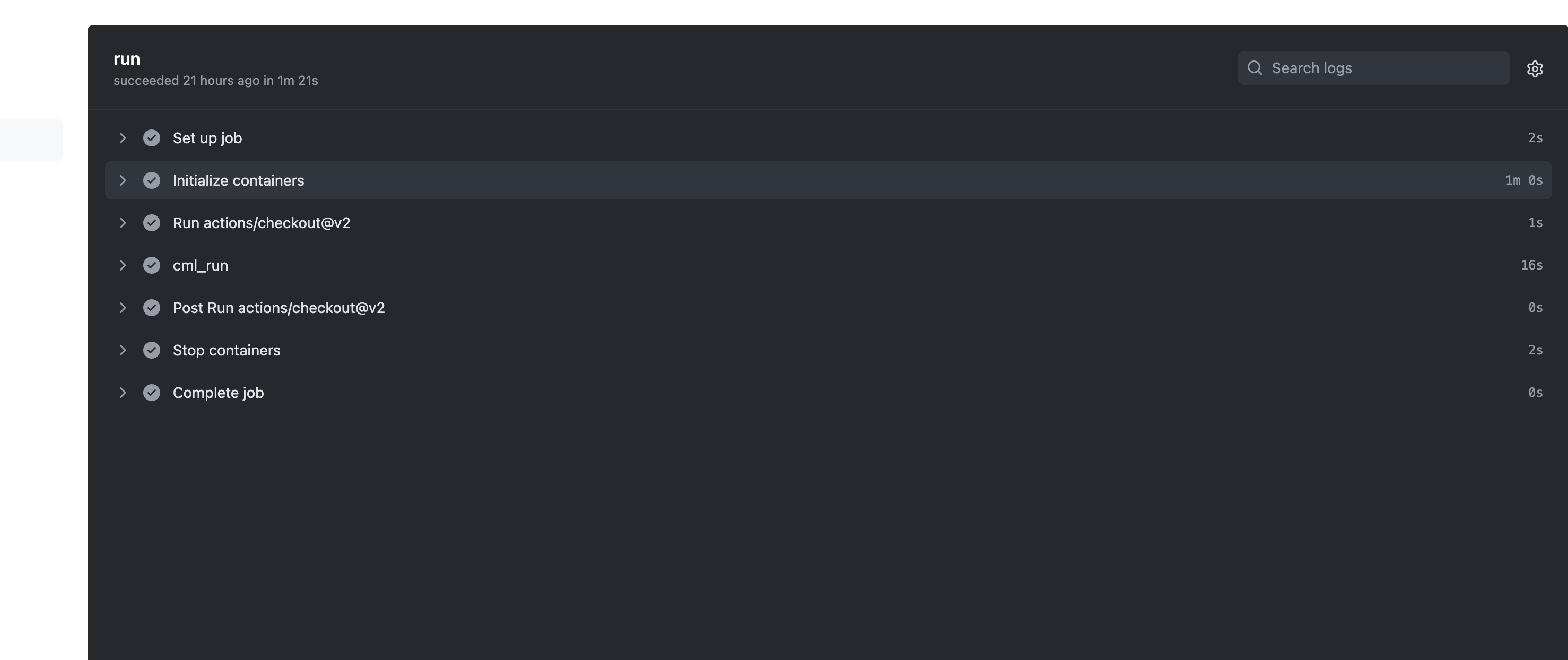
pip install -r requirements.txt
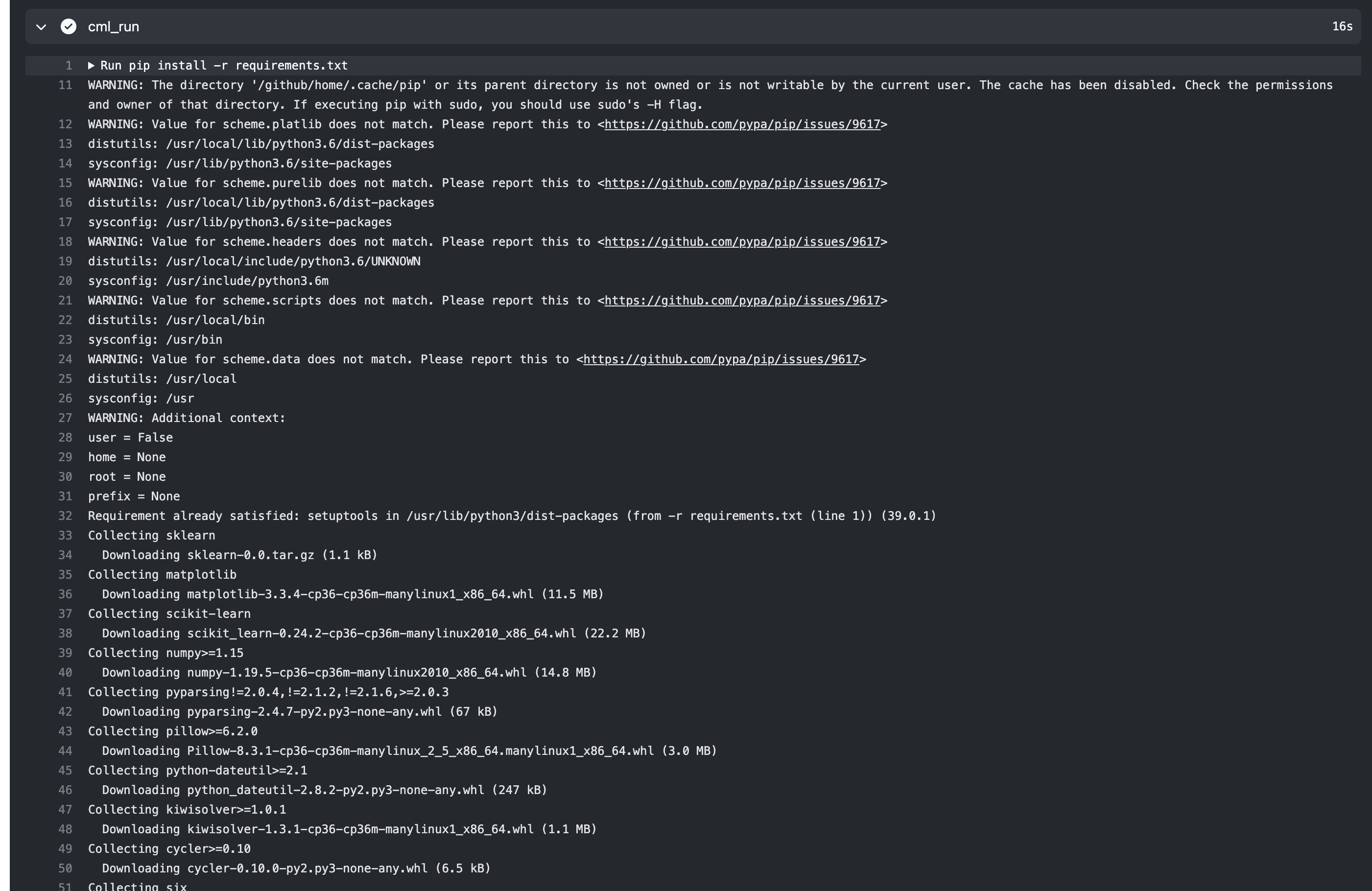
python train.py

dvc
dvc demo演示
第一节介绍了基于github actions,如何去做持续机器学习的工作流,算是一个简单的demo,接下来演示,当训练数据过大时,github无法使用时,应该如何处理,这里我们先做个演示,后续再来讲解。
先安装个dvc
pip install dvc
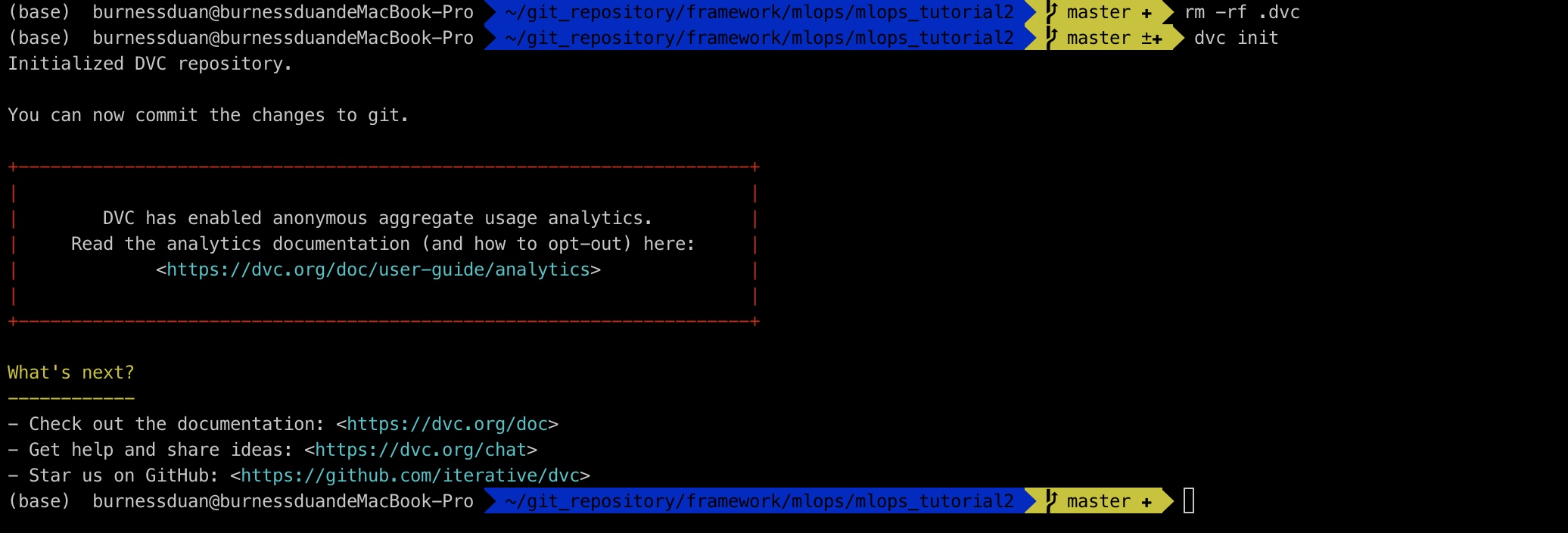
dvc init 有个报错
ERROR: unexpected error - 'PosixPath' object has no attribute 'read_text', 这里后面遇到experiments,又跳转会pip安装,并且卸载 pathlib即可: pip uninstall pathlib.
改用安装包
git clone https://github.com/burness/mlops_tutorial2
在google 云硬盘上创建一个目录, 复制folders之后的字段
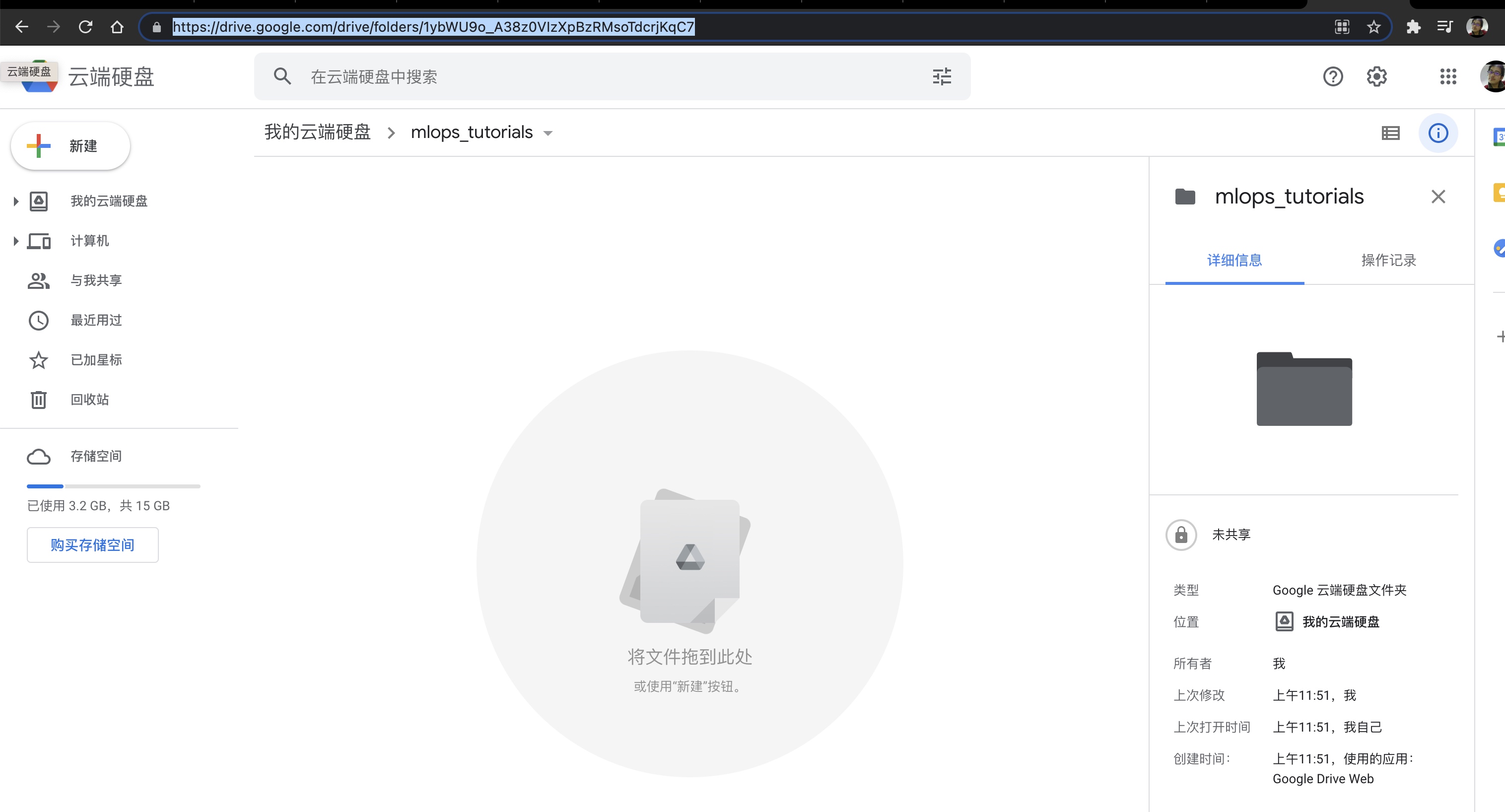
dvc remote add -d mlops_toturial2 gdrive://1ybWU9o_A38z0VIzXpBzRMsoTdcrjKqC7
commit and push
运行代码get_data.py, 下载需要使用的数据文件

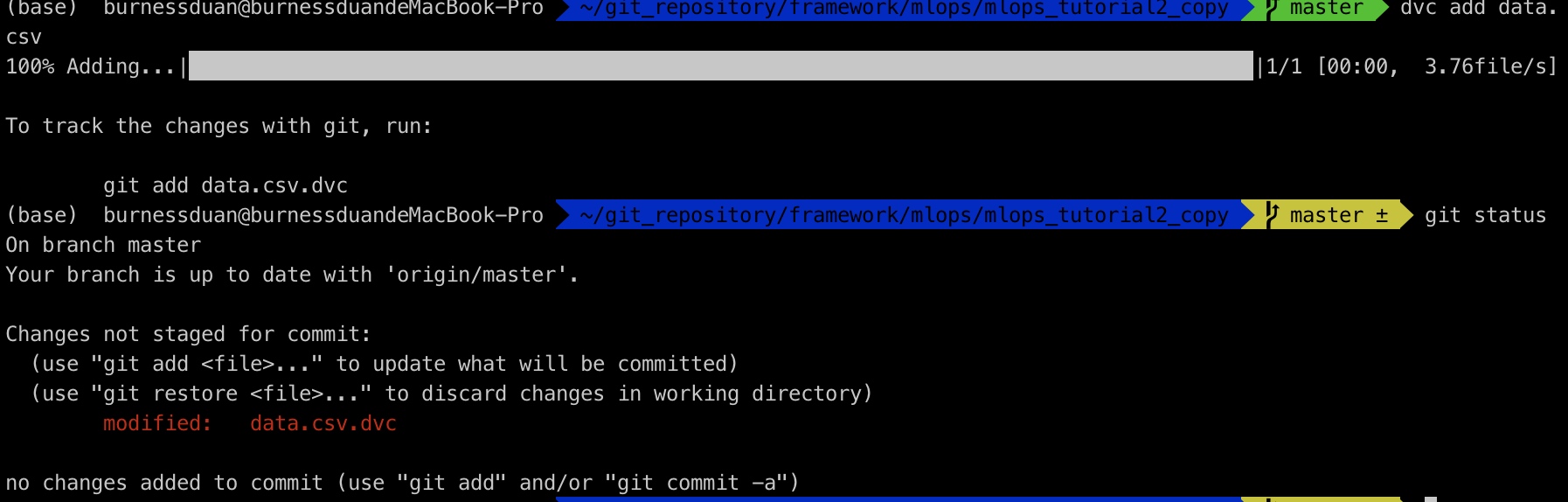
运行dvc add data.csv
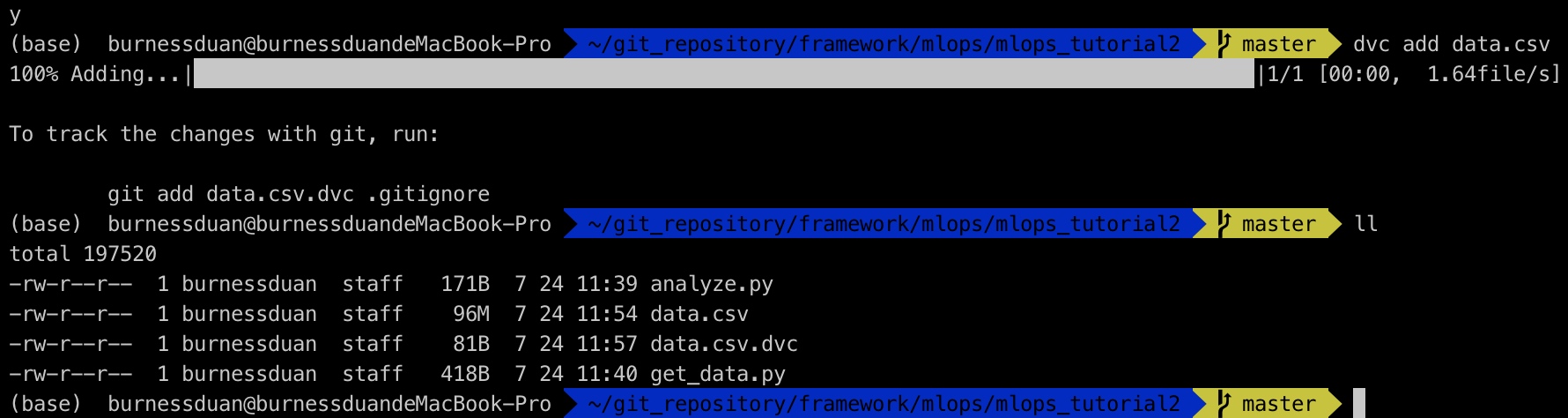
commit and push:
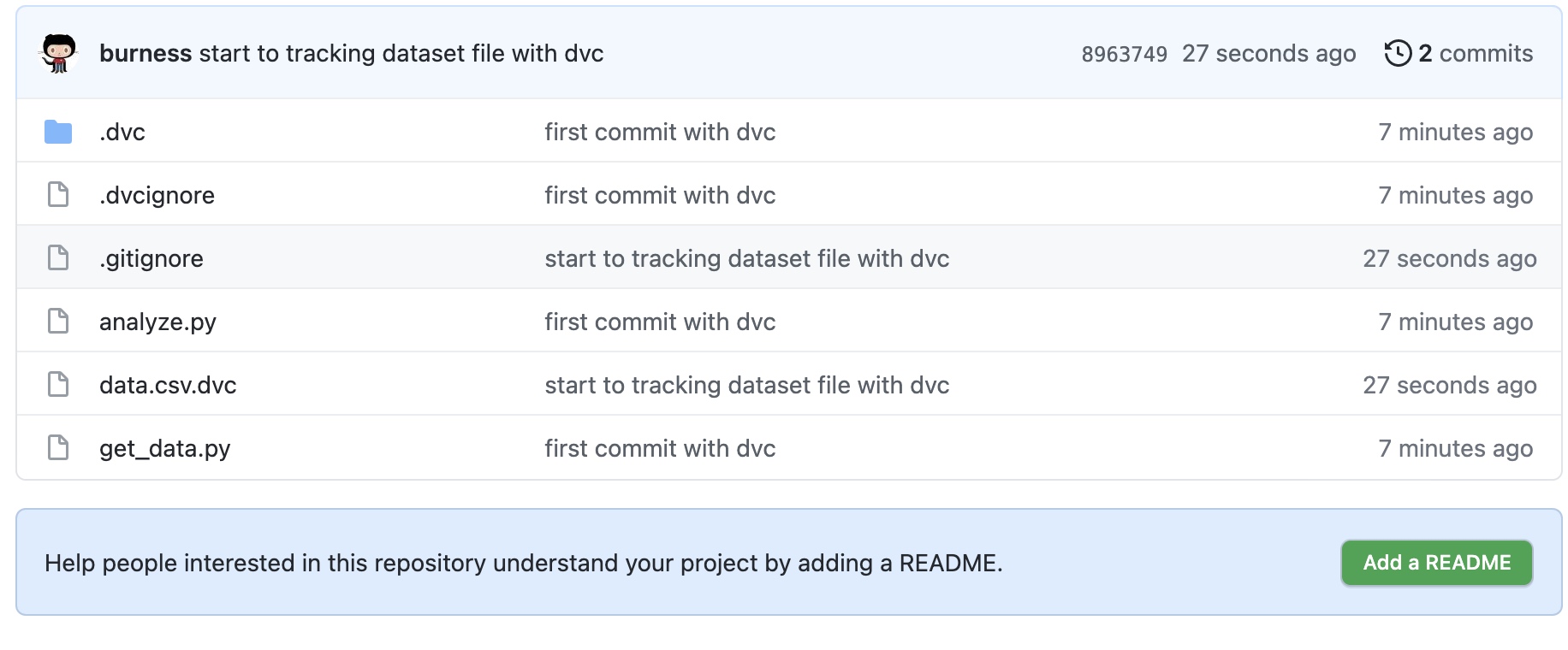
dvc 推送数据到google drive:

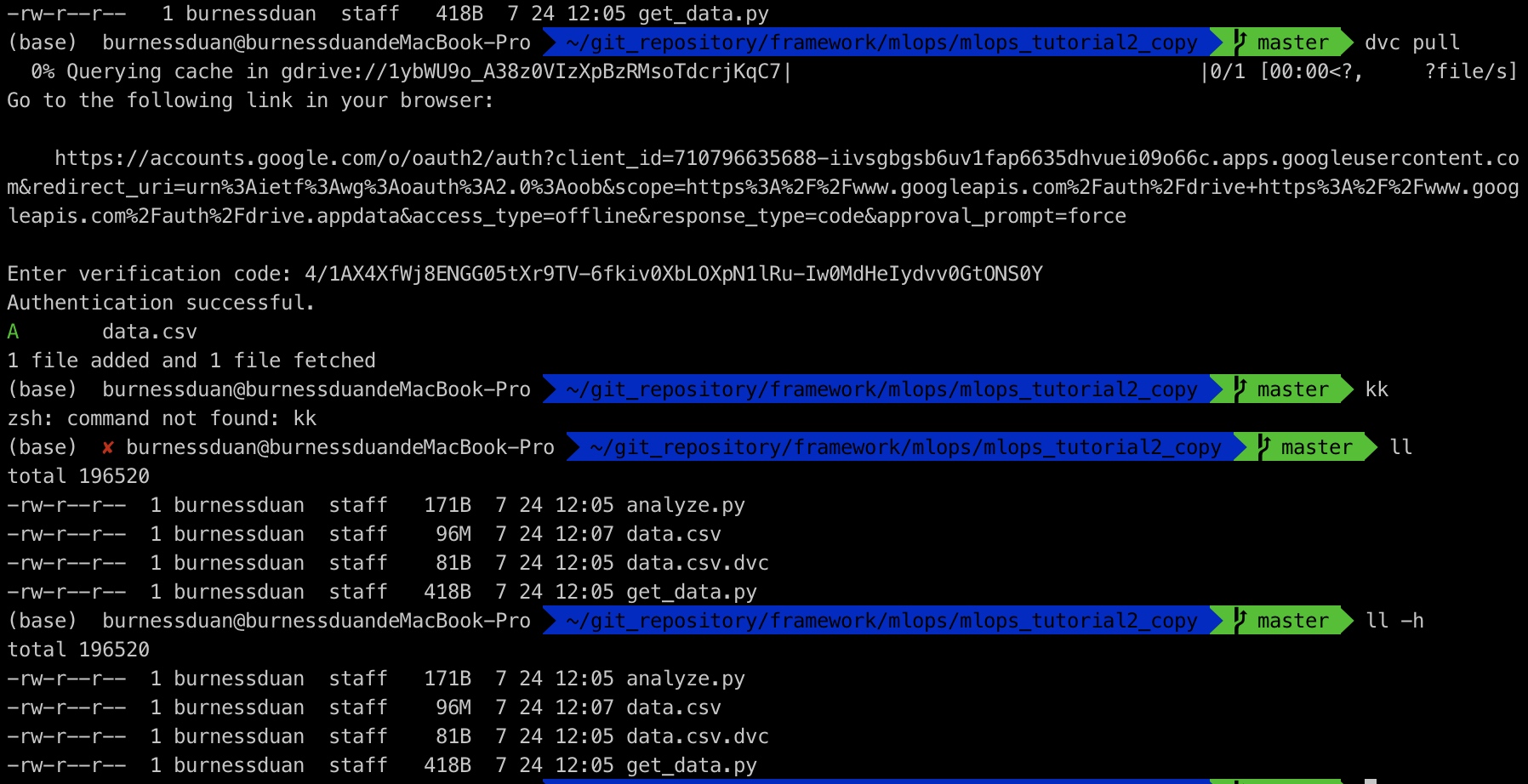
由于是第一次登陆, dvc需要你将图上链接粘贴到浏览器,然后得到一个验证码,复制进来,然后就开始数据push:
名字有一个变化:
因为我在公司,可以看外网资料, 这边没有两台电脑,为了方便演示, 我从github上clone项目代码到另一个目录:
dvc pull:
dvc 功能详解
数据与模型版本管理:
如前面一小节里, 我们dvc add data.csv, 生成data.csv.dvc, 那么我们看下对应dvc里面的内容:

那么,我们现在对数据 做一些更改,删除两行数据后,重新dvc add:
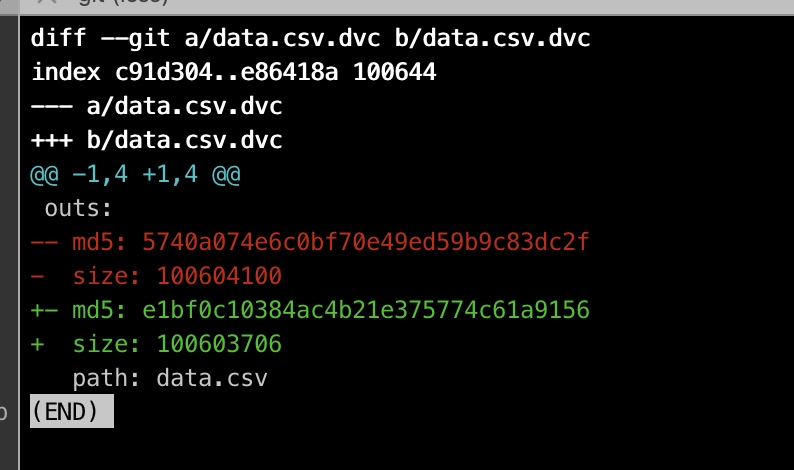
git 提交, dvc push:

我们到google drive上看, 又多了一个版本:
到现在为止, 我们有那个dataset, 怎么转回到之前的那个数据集呢?先git checkout 某个版本,然后dvc checkout即可
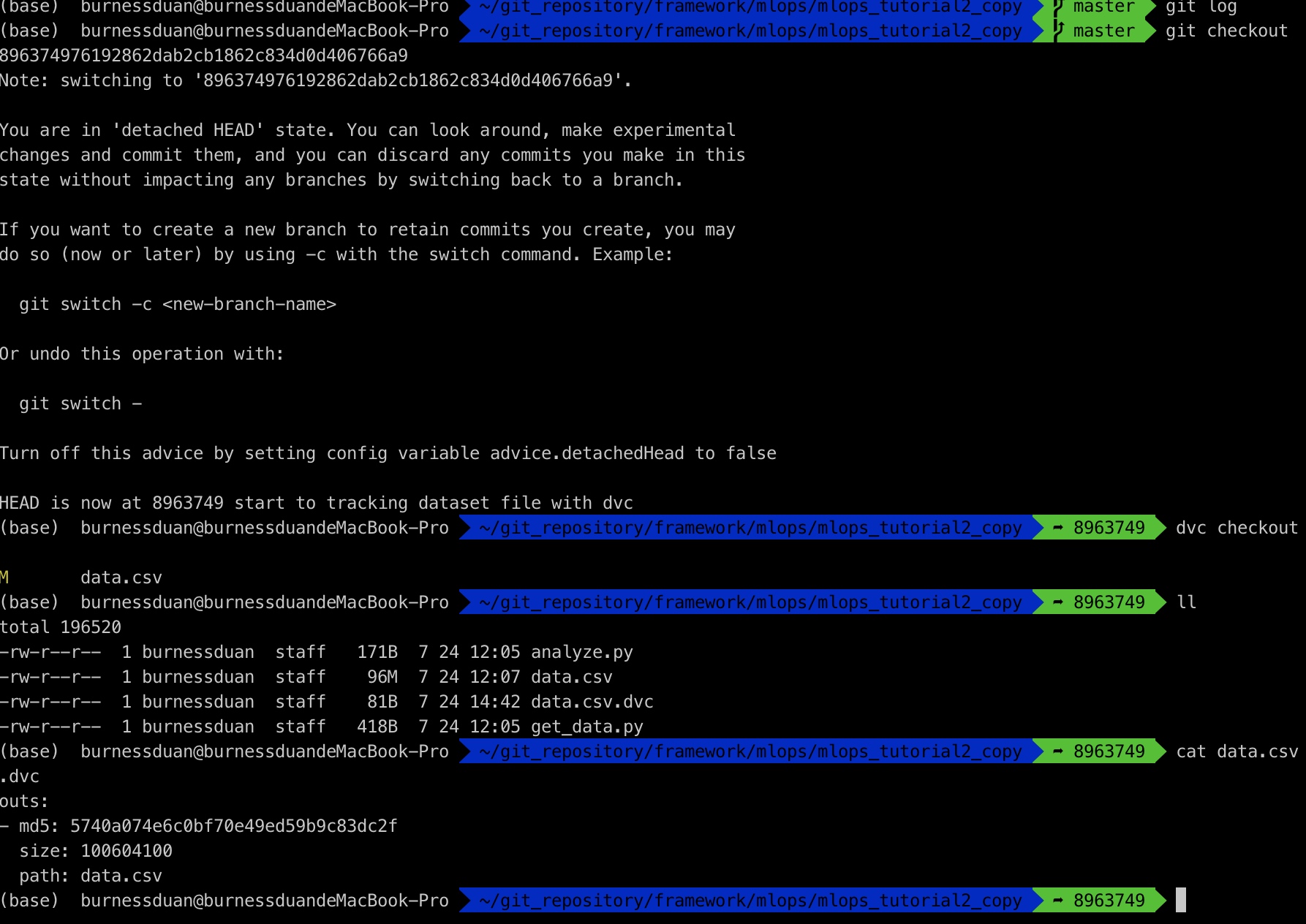
我们的数据就回来了,更好地一种是通过branch 来管理,这里就不尝试了,大家可以试试。
数据、模型访问
dvc list https://github.com/burness/mlops_tutorial2可以直接列出,项目当中使用dvc保存的数据文件,而注意这些文件并没有保存在github上。

dvc get https://github.com/burness/mlops_tutorial2 data.csv,可以在任意路径来download数据:

其他命令,如dvc import可以具体去看相关帮助信息了解;
数据结合pipeline
前面演示了如何使用dvc管理你的dataset文件,当然model文件也可以同样管理,但是这还不够,接下来会演示dvc如何保存数据的pipelines,在演示之前,我们拿到演示需要的代码:
wget https://code.dvc.org/get-started/code.zip
unzip code.zip
rm -f code.zip
安装数据处理所需的依赖:
pip install -r src/requirements.txt
运行命令:
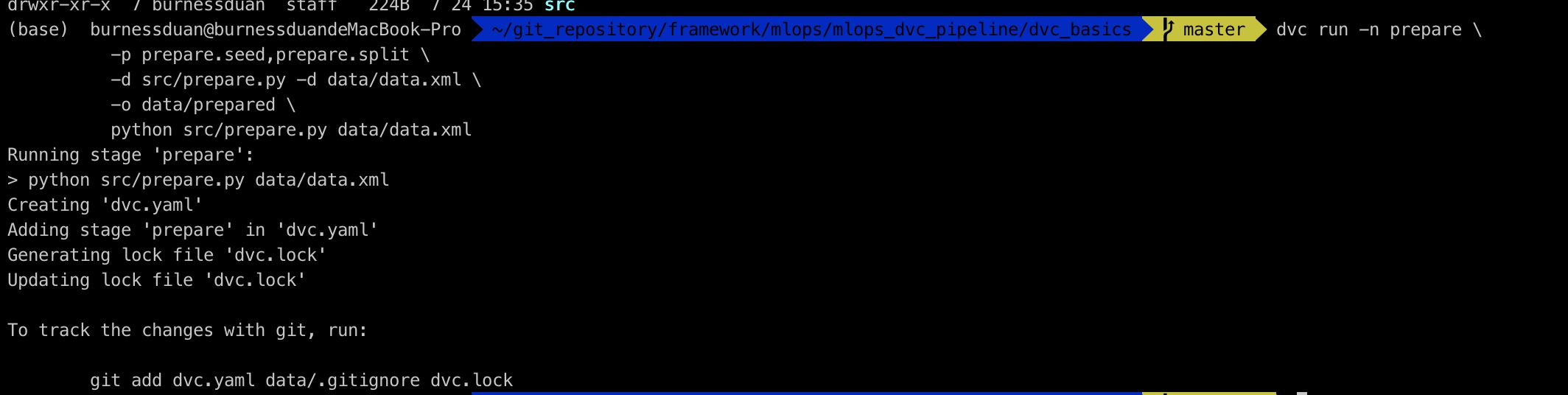
dvc run -n prepare \
-p prepare.seed,prepare.split \
-d src/prepare.py -d data/data.xml \
-o data/prepared \
python src/prepare.py data/data.xml
将数据文件按对应参数,切分成train.tsv与test.tsv:

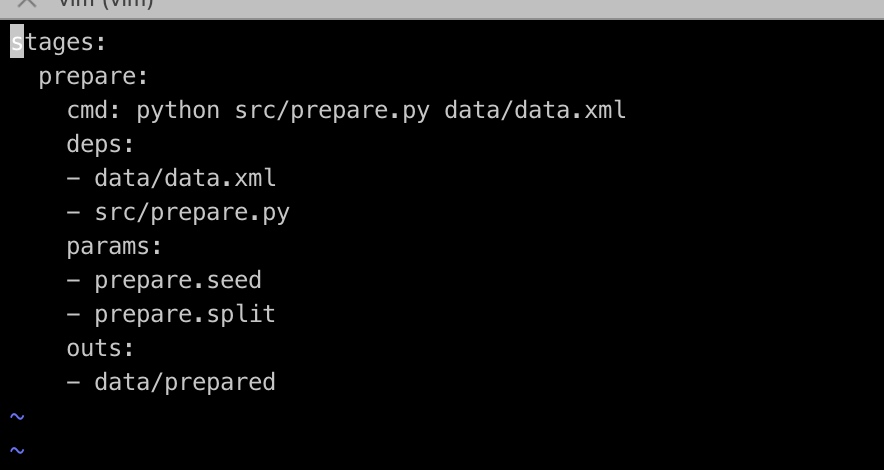
对应dvc.yaml里内容记录:
下一步,将prepare的数据进行特征处理:
dvc run -n featurize \
-p featurize.max_features,featurize.ngrams \
-d src/featurization.py -d data/prepared \
-o data/features \
python src/featurization.py data/prepared data/features
yaml文件如下:
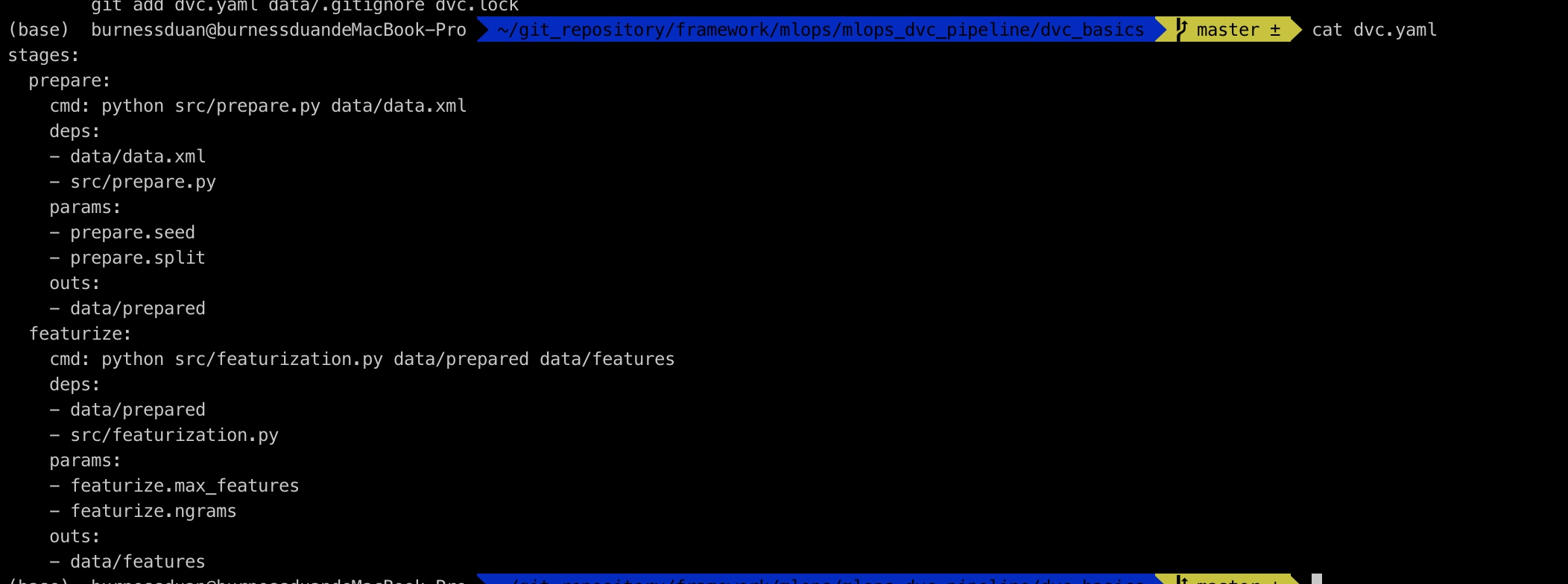
继续增加训练过程:
dvc run -n train \
-p train.seed,train.n_est,train.min_split \
-d src/train.py -d data/features \
-o model.pkl \
python src/train.py data/features model.pkl
相关产出:

dvc.yaml文件如下:
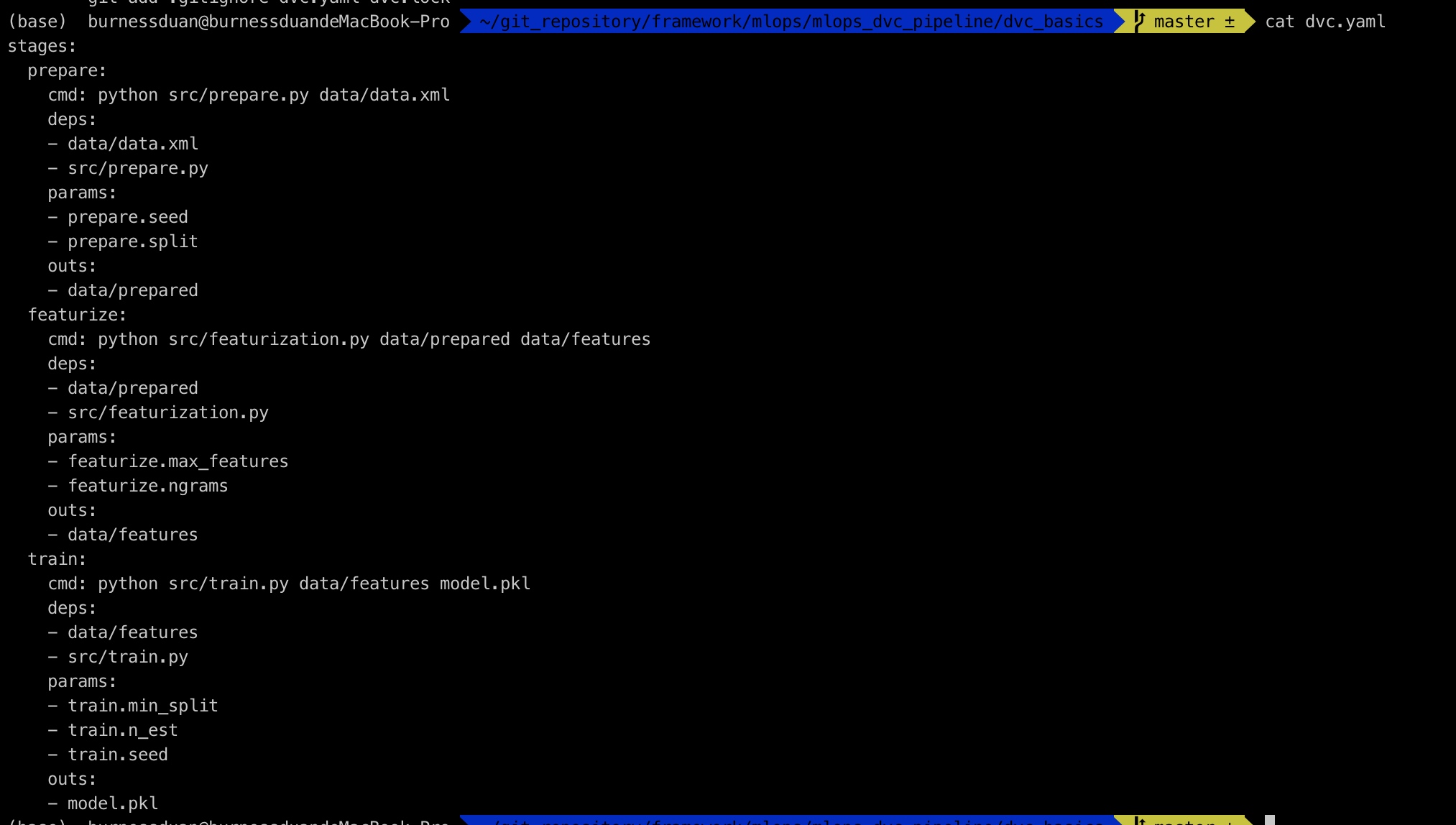
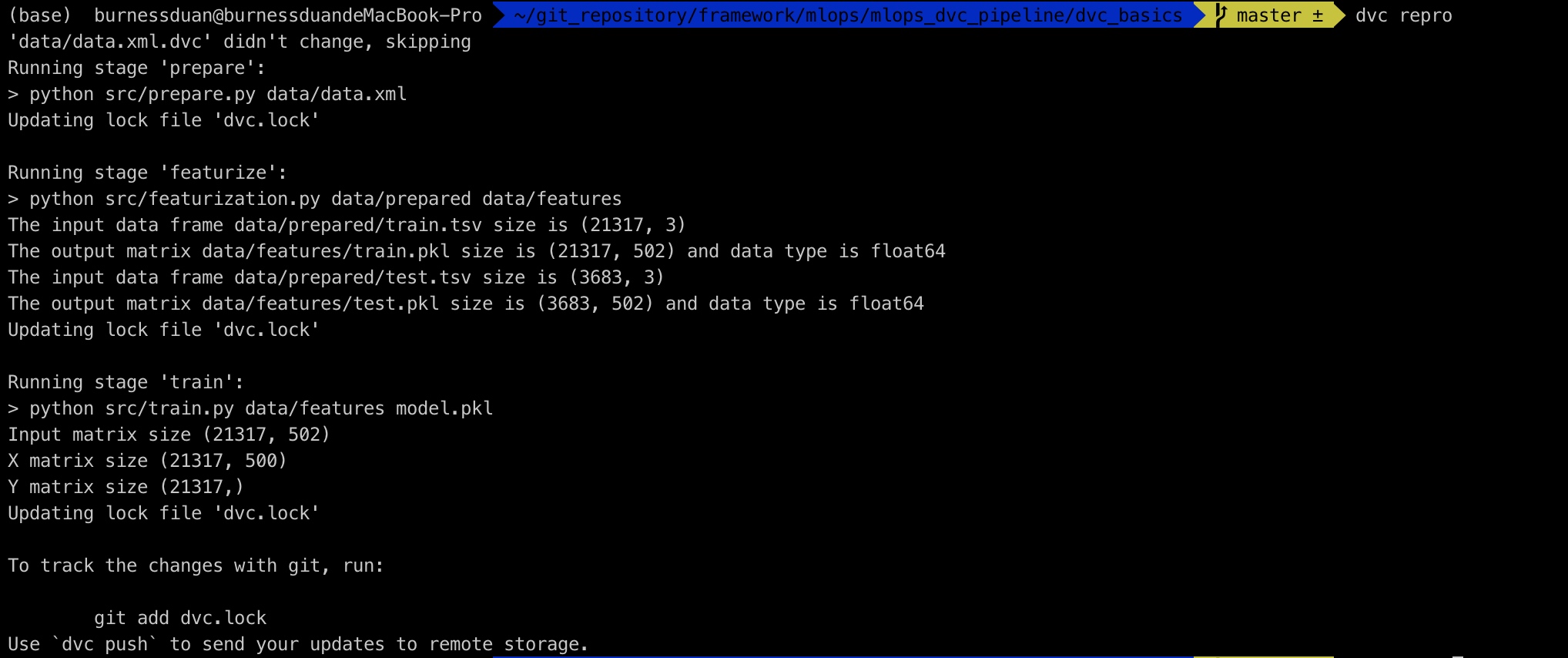
接下来只需要执行dvc repro,即可重现dvc pipeline:

我们修改下params里面的参数split:0.20->0.15, n_est:50->100:
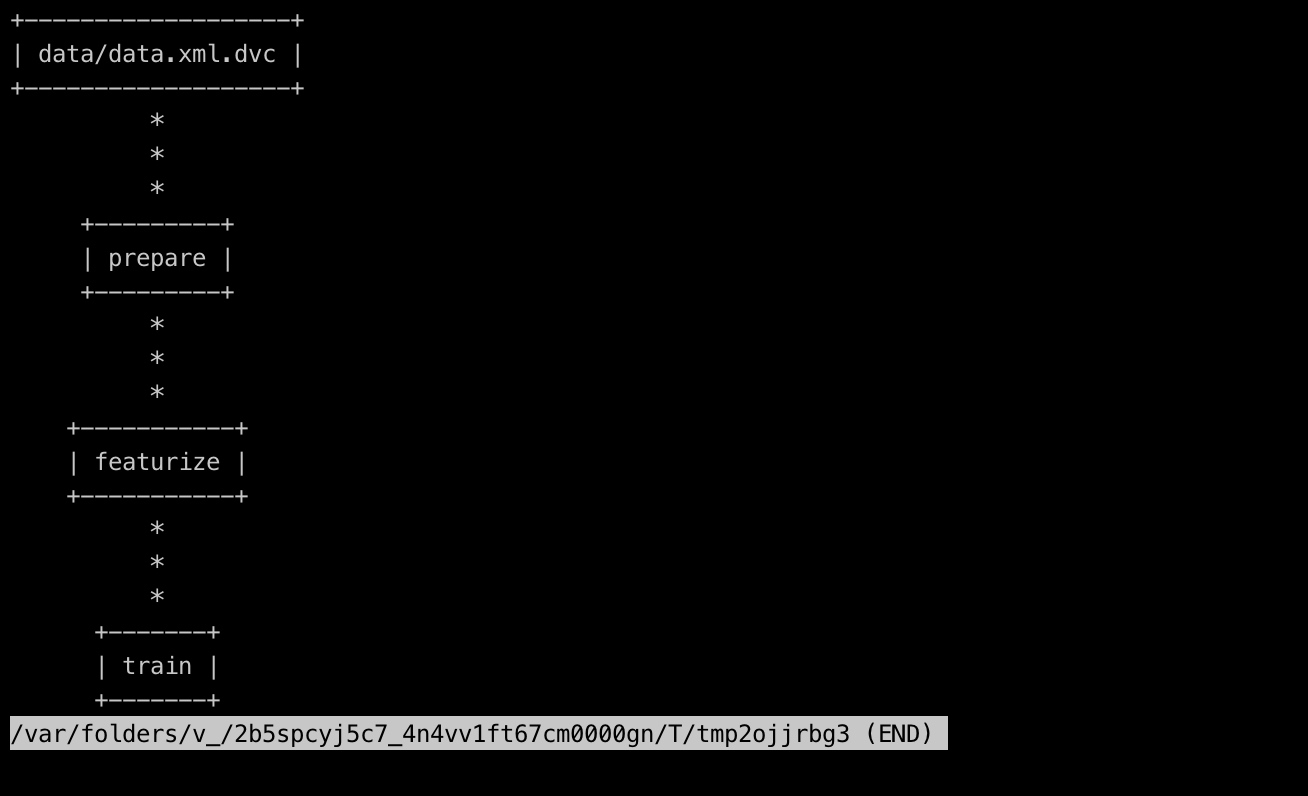
最后dvc dag:
pipeline与metric、parameter、plots结合
继续上面的演示来, 我们构建如上图的一个pipeline之后,接下来做模型的评估, 其中-M指定该文件为metric文件, --plots-no-cache 表明dvc不cache该文件:
dvc run -n evaluate \
-d src/evaluate.py -d model.pkl -d data/features \
-M scores.json \
--plots-no-cache prc.json \
--plots-no-cache roc.json \
python src/evaluate.py model.pkl \
data/features scores.json prc.json roc.json
dvc.yaml又增加evaluate过程, 其中evaluate生成对应的score.json, prc.json, roc.json:
查看score.json:

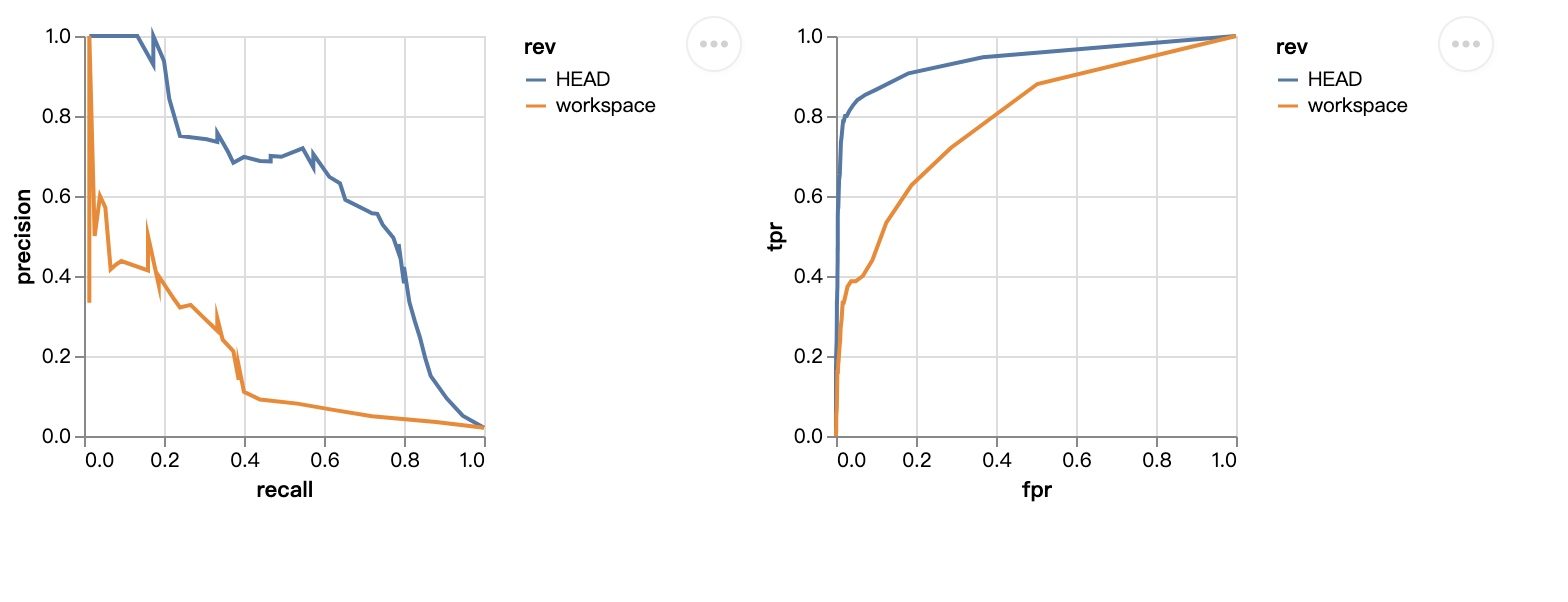
dvc plots modify prc.json -x recall -y precision
dvc plots modify roc.json -x fpr -y tpr
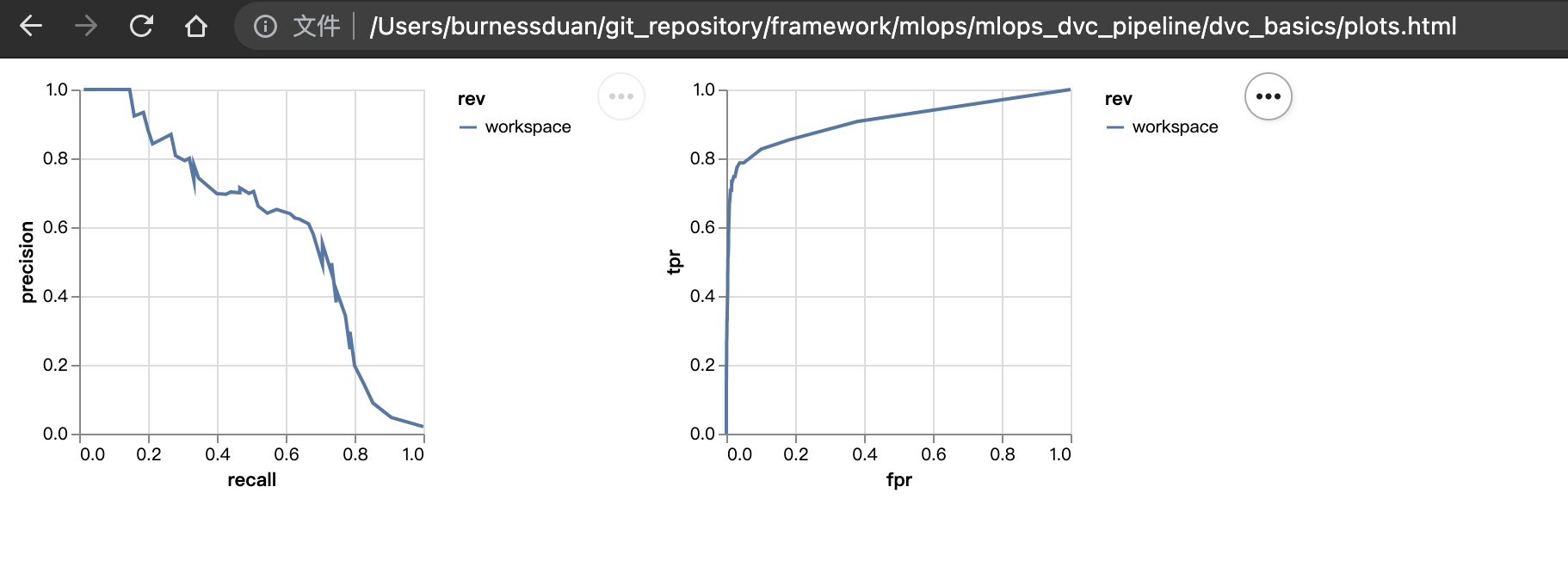
运行dvc plots show:
修改params.yaml中的max_features=1500, ngrams=2。
重新运行整个pipeline:
dvc repro
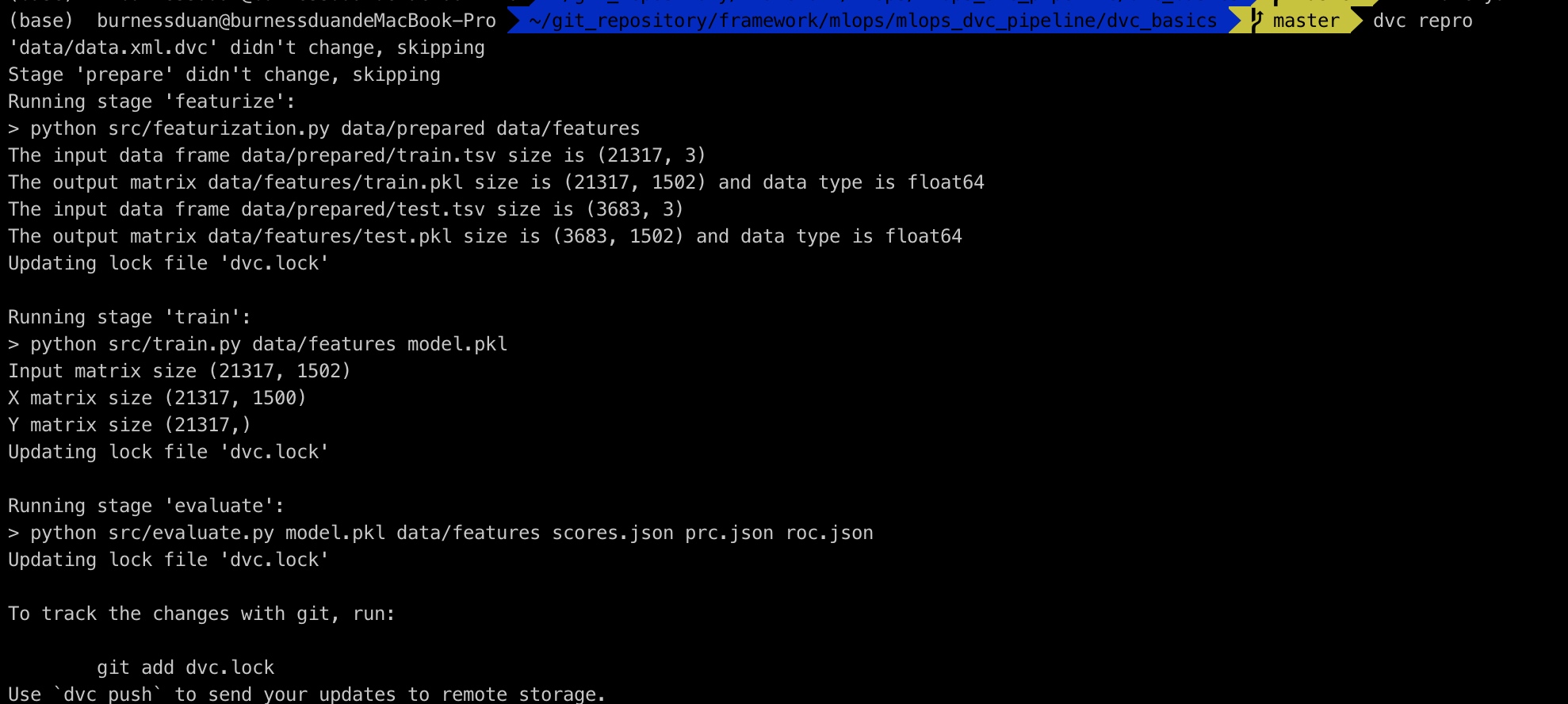
git保存&提交:
git add .
git commit -a -m "Create evaluation stage"
再次修改params.yaml中的max_features=200, ngrams=1, 运行整个pipeline:


dvc plots diff画出不同参数版本的效果差异:
dvc与experiments
在dvc中,使用experiments来构建不同实验组,来进行超参的调试:
dvc exp run --set-param featurize.max_features=3000 --set-param featurize.ngrams=2将max_features配置为3000, 并且运行整个pipeline:
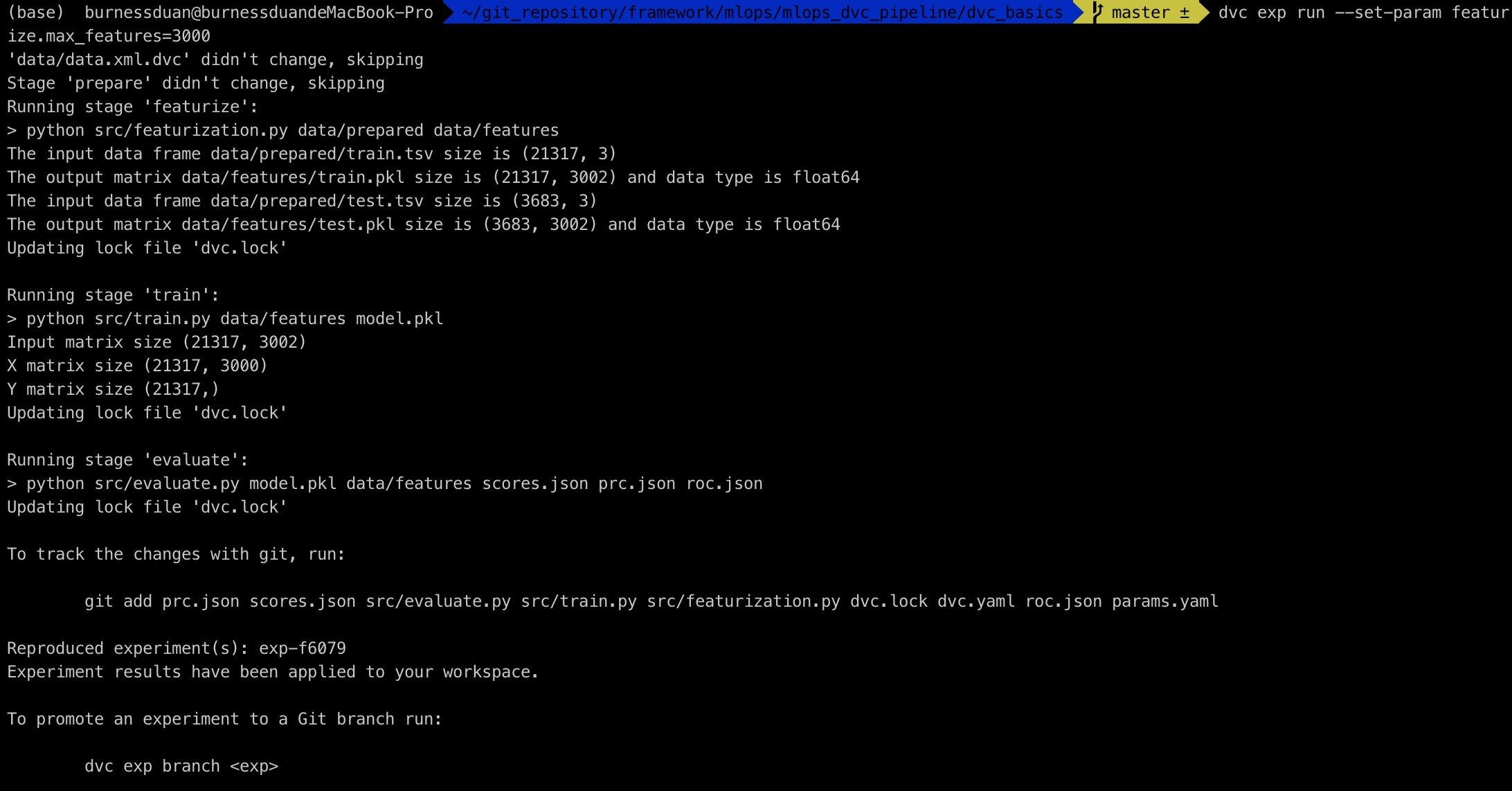
对比实验:

缓存实验队列:
dvc exp run --queue -S train.min_split=8
dvc exp run --queue -S train.min_split=64
dvc exp run --queue -S train.min_split=2 -S train.n_est=100
dvc exp run --queue -S train.min_split=8 -S train.n_est=100
dvc exp run --queue -S train.min_split=64 -S train.n_est=100
开始运行, 其中并行任务为2, 这里遇到个小插曲,改用pip安装即可,写在pathlib即可:
dvc exp run --run-all --jobs 2
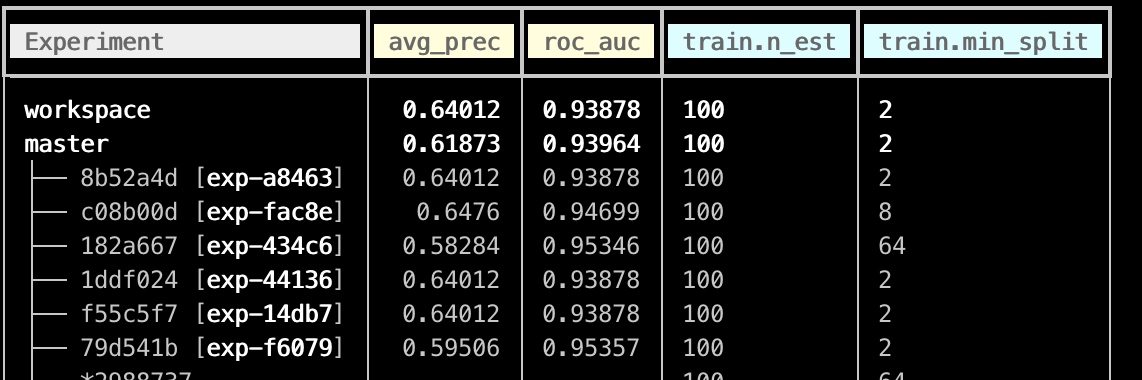
我们看到最好的auc 效果为79d541b, 实验id为exp-f6079, 我们将这个持久化,并且查看现在score.json:

dvc push 保存至远端

这里我push失败dvc exp push gitremote xx, 应该是和我项目git remote前后不一致相关,,dvc exp pull gitremote xxx ,小问题, 这里不影响 不做过多计较;
##总结
不知道大家有没有把文章看完,很长(后续应该还有cml和dvc其他方面的实践,比如self-hosted runner, 太长了就拆开)。不过归根到底,无非就是那么几块东西:
- 如何将你的算法代码、数据、配置、模型、实验管理起来;
- 将你所管理的信息,能够分享、复制、快速复现;
- 所有的流程都可以记录,可以版本管理;
文章上面相关的技术工作是iterative.ai/这家公司的成果。虽然无法直接拿到企业中使用,但是其中的思想以及设计理念值得学习。接下来的文章,我将参考他们的设计思想,试着去设计符合企业界的mlops。 有兴趣,欢迎讨论。